






Ich war am Wochenende auf der PyData in Berlin – einer Python Konferenz und dessen Anwendung für (große) Daten, d.h. Maschine Learning, Datenbanken, Webanwendungen, Data Wrangling usw.
War genau so eine Konferenz, die man, je nach Talk, in diesem Data Science Venn Diagramm einsortieren kann:
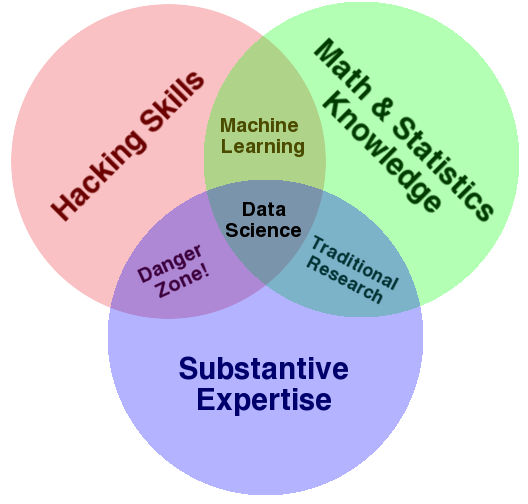
The Data Science Venn Diagramm by Drew Conway under CC-BY-NC Lizenz
Wahnsinn!
Unter anderem sprachen die Jungs von Continuum.io mal generell zu der OpenSource Community hinter Python und dem ganzen Enthusiasmus, der nötig ist, um eine solche Vielfalt und Qualität hin zu bekommen:
Die gemeinnützige NumFocus Organisation versucht die Community zu stützen und z.B. Stipendien, Events, Reisekosten, Teilnahmegebühren etc. zu finanzieren. Eine Herausforderung dabei ist das Trittbrettfahrerproblem. Das heißt es wird mit Hilfe der freien Software in Firmen Gewinn erzielt, diese geben aber davon nichts zurück an die Community. Es müsste eine Art Selbstverständnis einziehen, welches jeden Geschäftsführer dazu bemüht zu sagen: OK, wir haben einen echt guten Auftrag mit OpenSource Software erledigen können und haben Lizenzkosten eingespart: Lass uns mal bissl was an die NumFocus Organisation spenden.
Ein weiteres Problem ist die sehr geringe Frauenquote. Dazu werden spezielle Events durchgeführt und spezielle Förderprogramme (Stipendien) vergeben usw., aber wie Hr. Oliphant in seinem Talk ja auch selbst sagt: Seine beiden Töchter haben kein Interesse am Programmieren. Ist eben vielleicht einfach so, man kann den Hund nicht zum jagen tragen. Aber wenn Frauen Interesse am Programmieren haben, dann ist es meiner Meinung nach noch nie so einfach gewesen einzusteigen. Die Türen stehen überall mit Sog offen.
OK, genug Allgemeines, gehen wir mal zum Technischen.
Talks
Dazu muss ich sagen, dass seeeeeehr viele Talks inhaltlich an mir vorbei gingen, weil ich einfach nicht das KnowHow hatte/habe, um das zu verstehen, was da erzählt wurde. Diese Auswahl hier ist also nicht wertend gemeint! Außerdem fanden immer 2 Talks gleichzeitig statt, sodass es ohnehin nur möglich war 50% live zu erleben.
Faster Than Google
Dieser Talk hat mich am meisten beeindruckt. Ein großer Kritikpunkt, den ich oft höre, ist, dass Python ja schön und gut sei, aber eben zu langsam. Der [@RadimRehurek] hat sich das Google word2vec Projekt mal angeschaut und einen Python Wrapper dafür geschrieben.
Das Projekt ermöglicht mit einem großen (Lern-)Datensatz an Wörtern (z.B. aus Büchern oder Google News Artikel) eine semantische Analyse. Beispiel:

Fahrzeug ist zu Spaß wie Zug zu …?
Und allein aus dem Auswerten und Lernen aus Google News Artikeln (100 Millarden Wörter), findet der Algorithmus eine wahrscheinlichste Antwort: …Hektik! :) Kann man selbst mal auf Radims Seite ausprobieren, er hat eine Word2Vec Web-App online.
Dessen noch nicht genug, hat er festgestellt, dass die pure Python implementierung ungefähr 120x langsamer ist als die C-Implementierung von Google. Er hat sich dann an ein paar Optimierungen gemacht und konnte aufschließen. Aber das hat ihn noch nicht befriedigt, er hat noch mehr optimiert und ist nun 120x schneller als die Google C-Implementierung! Und alles ganz unaufgeregt und sympathisch vorgetragen:
Wow!
Maschine Learning sollte einfacher werden
Andreas Müller [@t3kcit] (Amazon, Scikit-Learn Maintainer) spricht darüber, dass nicht immer mit Kanonen auf Spatzen geschossen werden muss.
Die meisten Probleme können auf einem Rechner gelöst/ausgeführt werden, es ist nicht immer Hadoop und ein riesen Cluster notwendig, auch wenn das gerade ‘In’ ist.
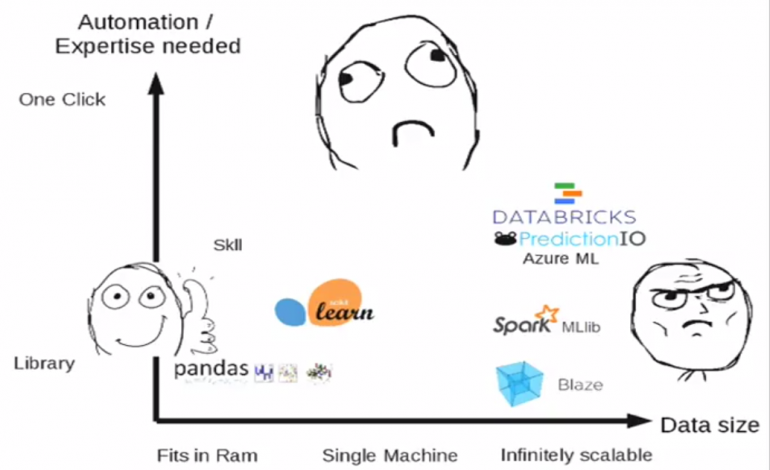
Screenshot aus Präsentation von Andreas Müller auf der PyData Berlin 2014
Er schlägt auch vor, dass die Tools noch einfacher werden könnten, denn letztlich ist die Auswahl an Verfahren ein relativ definierter Ablauf, der sich einfach aus der Struktur der Datensätze ergibt. Ein Maschine Learning Toolkit (scikit-learn), könnte also sogar selbst anhand der Daten auswählen, welches Maschine Learning Verfahren (z.B. SVM, nearest neighbors, random forest) das Richtige ist, selbst wenn der Anwender gar nicht versteht, wie das Verfahren im Detail funktioniert.
Maschine Learning für ALLE!
Funfact: Nach meiner ganz ganz dezenten Kritik an den Amazon Empfehlungsalgorithmen im Deutschlandradio Kultur Breitband Podcast (man kauft einen Kühlschrank und bekommt danach Kühlschränke vorgeschlagen), hab ich ihn gefragt, wieso das derzeit so schlecht ist.
Er musste lachen und sagte, dass da eine ganze Menge Leute dran arbeiten das zu lösen. Und die Antwort ist verblüffend: Tatsächlich zeigen die Daten, dass Leute die Kühlschränke kaufen, danach einen Kühlschrank kaufen. Warum? Weil es Reseller sind, die über ihren Privataccount für ihr Geschäft Kühlschränke einkaufen.
Man könnte es natürlich Hard-Coden, so nach dem Motto: “Wenn letzte Bestellung ein Kühlschrank, dann nicht wieder einen Kühlschrank vorschlagen”. Aber das wird schnell so komplex (wo die Grenzen ziehen? Fernseher auch? iPod auch?), dass es gar nicht erst angefangen wird. Es muss vom Maschine Learning Algorithmus selbst heraus gefunden werden. Not Bad!
How to Spy with Python
Wer mal mit offenem Mund vorm Rechner sitzen möchte, dem empfehle ich den Talk von Lynn Root [@roguelynn], die etwas über die historische Entwicklung der Überwachung (PRISM, XKeyScore etc.) erzählt und dann mal beispielhaft ein bisschen Internet-Traffic mit Scapy und anderen Tools auswertet.
“This talk will walk through what the US government has done in terms of spying on US citizens and foreigners with their PRISM program, then walk through how to do exactly that with Python.”
Wer also das nächste mal in einem “Free-WIFI” eingeloggt ist und auf Webseiten ohne HTTPS surft und dort schön Passwörter eingibt oder Bilder hoch/runter lädt, der teilt das möglicherweise mit allen im gleichen WLAN. Gegen das Absaugen direkt beim Internetprovider kann man nicht viel machen, außer den Tor Browser benutzen, was aber gleich wieder verdächtig macht. Zwickmühle.
Data Mining und Visualisierung: Trends in Research Papers und Foursquare Locations
Benedikt Köhler [@furukama] zeigt (ab 20:00min), wie man wissenschaftliche Veröffentlichungen aus Google Research und Scholar holt und semantisch einander zuordnet. Man kann Trends und Buzzword-Bingo spielen und heraus bekommen, welche Veröffentlichung (zumindest nach Abstract) einer anderen sehr ähnelt.
Weiterhin zeigt er, wie man Foursqure Daten nutzt, um wichtige Orte in einer Stadt zu finden, denn das hat nichts mit der Anzahl der Check-Ins zu tun!
Moors Law und was Maschine Learning mit dem neuen iPhone zu tun hat
Ein Talk, den ich nur zur Hälfte verstanden habe, der aber mit Sicherheit eine riesen Sache ist, wurde von Trent McConaghy gehalten. Er beschreibt, weshalb es in den nächsten Jahren passieren wird, dass 2 Leute das gleiche elektronische Gerät gekauft haben, aber unterschiedliche Erfahrungen damit machen, z.B. ein Display ausfällt oder der Akku nur 1/2 so lange hält. Chips werden kleiner, Atome aber nicht. Alle Schaltkreise testen geht nicht mehr, weil es zu lange dauern würde.
“How do we keep making ever-smaller devices? How do we harness atomic-scale physics? Large-scale machine learning is key. The computation drives new chip designs, and those new chip designs are used for new computations, ad infinitum. High-dimensional regression, classification, active learning, optimization, ranking, clustering, density estimation, scientific visualization, massively parallel processing — it all comes into play, and Python is powering it all.”
Und viele, viele mehr…
Natürlich gab es noch viel, viel mehr, welche ich aber im Detail nicht wiedergeben kann. Diese sind zum Teil auch hier zu finden: https://www.youtube.com/user/PyDataTV/videos
Dabei ist u.a. auch meiner (der thematisch nicht so ganz auf die Konferenz gepasst hat), aber ich habe viele Rückfragen dazu bekommen, sodass ich zumindest das Gefühl hatte, dass der Kalman Filter für viele interessant ist. Und wie Travis Oliphant sagte: Man muss in einer Community immer auf die Heterogenität und externen Einfluss achten, sonst kocht man nur sein eigenes Süppchen.
Fazit
Ich hatte das Gefühl, dass ich dort zwischen den richtig, richtig, richtig guten Jungs & Mädels sitze. Also die richtigen Experten. Die, die wissen wie es geht, die etwas über Nacht auf die Beine stellen können. Die wirklich Probleme lösen können. Gefühlt hatte jeder einen Doktorgrad (PhD) und konnte (trotzdem) wirklich was auf dem Laptop, denn programmiert wurde jederzeit, überall.
Wäre ich ein Recruiter oder Human Resource Typ, dann würde ich keinen Cent mehr für Recruitingmessen ausgeben, sondern mich auf die nächste Python Konferenz begeben (z.B. als Sponsor) und meinen besten Entwickler hin schicken (nicht die Marketing-Abteilung) und dort mit den Leuten in’s Gespräch kommen. Eine Firma, die sich mit interessanten Projekten (ja, man muss auch mal wirklich Einblicke geben!) vorstellt und eine so coole Konferenz unterstützt, die wirkt automatisch sympathisch und zieht Entwickler an.
Außerdem war das Essen vom BCC gut, das WLAN war stabil und schnell und es gab Fritz Kola und Obst kostenlos das ganze Wochenende. Und Mate natürlich.

Recruiting: The right language!

Dr. Yves Hilpisch Talk in Raum B09

Super Versorgung vom Berlin Congress Center! Danke

-

- Super Versorgung vom Berlin Congress Center! Danke
-

- Dr. Yves Hilpisch Talk in Raum B09
-

- Recruiting: The right language!

