




Es gibt praktisch kein informationsverarbeitendes Gerät, was ohne Algorithmen auskommt. Dabei sind die guten Dienste immer Artificial Intelligence getrieben. Ob die Produktvorschläge bei Amazon, die Spracherkennung von Google, Siri oder Shazaam. Alles das Ergebnis von Maschine Learning Algorithmen.
Einen sehr schönen Einstieg in die Thematik “Algorithmen”, zeigt dieses Video:
Doch wie geschieht es nun, dass ein Computer so lernen kann?
Wenn Computer ‘lernen’ sollen, kann man grob in 2 Kategorien unterscheiden:
- Supervised Learning
- Unsupervised Learning
Beim Supervised Learning wird dem Algorithmus eine große Anzahl an Daten zur Verfügung gestellt, die nach einer bestimmten Eigenschaft gelabelt sind. Zum Beispiel werden 100 Fotos von Tassen, die auch als “Tassen” dem Maschine Learning Algorithmus vorgestellt werden, genutzt. Nun ist ‘viel’ relativ. Mit 100 Tassen wird kein Maschine Learning Algorithmus gute Ergebnisse bringen.
Größe der Datensets ist begrenzt
Hier wird nun das Problem deutlich. Möchte man einem Algorithmus beibringen in beliebigen Fotos Tassen zu finden, so sollte man 100.000 Tassen, besser 1mio Tassen, noch besser 10mio Tassen fotografieren und als Tassen labeln und damit den Algorithmus füttern.
Schnell wird klar, dass es nur für wenige Problemstellungen ausreichend große Datensets gibt. Ist das Datenset nicht vorhanden, müssen Menschen sich hinsetzten und Dinge manuell labeln, damit der Computer etwas zum lernen hat. Das ist nicht sehr effektiv.
Hier kommt nun der Vorteil des Unsupervised Learning zum Tragen.
Unsupervised Learning kann unbegrenzt viele Daten verarbeiten: Und wird besser!
Die Algorithmen zum Unsupervised Machine Learning können auch mit Daten lernen, die nicht gelabelt sind. Plötzlich wird ein Google Bildersuche oder YouTube oder flickr zu einem riesigen Datenpool zum lernen. Als Beispiel bringt Andrew Ng das Sparse Coding an.
Sparse Coding
Dabei wird ein Bild z.B. in 14×14 Pixel große Teile \(x\) zerlegt, welche den Input des Learning Algorithmus (Neurales Netzwerk) bilden.

Quelle: Sreenshot aus RSS2014: 07/16 09:00-10:00 Invited Talk: Andrew Ng (Stanford University): Deep Learning
Anschließend wird mit dem “Sparse Coding” genannten Verfahren eine Linearkombination von Matrizen \(\phi\) mit dem Faktor \(a\) gewichtet, sodass jedes 14×14 große Teilbild \(x\) näherungsweise durch
$$x \approx \sum_{j=1}^{64} a_j \phi_j$$
ausgedrückt werden kann. Grafisch dargestellt sieht dies in etwa so aus:
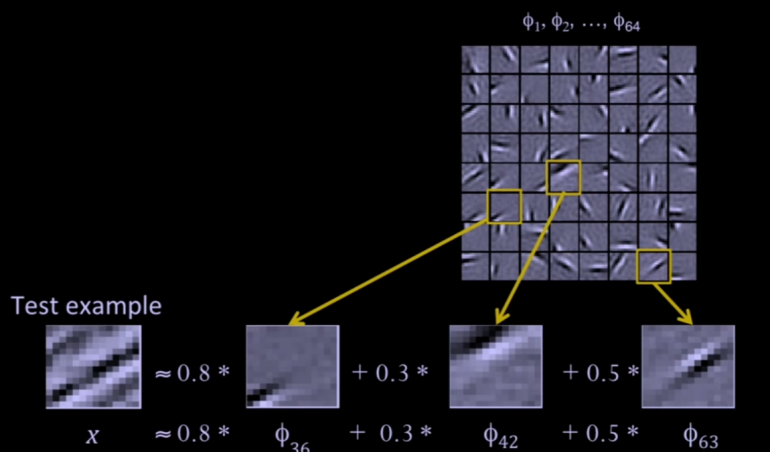
Quelle: Sreenshot aus RSS2014: 07/16 09:00-10:00 Invited Talk: Andrew Ng (Stanford University): Deep Learning
Im Bild wird das Testbild ungefähr durch die Linearkombination von \(0{,}8 \cdot \phi_{36} + 0{,}3 \cdot \phi_{42}+ 0{,}5 \cdot \phi_{63}\) beschrieben. Die meisten anderen Werte für \(a_j\) sind 0. Deshalb der Name ‘sparse’. Das Aussehen der \(\phi_i\) ergibt sich durch numerische Minimierung einer Kostenfunktion.
Die Wichtung der Werte sind nun die so genannten Neuronen. Mehr dazu auf deeplearning.stanford.edu…
Lernen durch YouTube Videos
Nun hat man sehr viele kleine 14×14 große Einzelneuronen, welche irgendwie zusammengesetzt eine Form ergeben. Je nachdem wie oft und wie zusammen gesetzt sich etwas passendes ergibt, lernt der Deep Learning Algorithmus selbstständig, was relevant sein könnte. Nach unzähligen Stunden YouTube Video, sah ein Neuron beispielsweise so aus:

Nach unzähligen YouTube Videos hat ein Neuron diese Form als ‘relevant’ eingestuft und sucht danach. Quelle: Sreenshot aus RSS2014: 07/16 09:00-10:00 Invited Talk: Andrew Ng (Stanford University): Deep Learning
Der Vorteil von Unsupervised Learning ist, dass das Ergebnis mit zunehmender Datenmenge immer besser wird. Eine sehr interessante Entwicklung. Der Vortrag ist auf jeden Fall seine Zeit wert. Allerhöchste Empfehlung! Seht selbst:
Andrew Ng: Deep Learning
Titelbild “Shodan” von Pascal von flickr.com unter CC-BY2.0 Lizenz



2 Comments