


Nehmen wir an man fährt mit seinem PKW Navi in einen Tunnel. Das GPS Signal ist weg. Trotzdem möchte man vielleicht angezeigt bekommen, dass man die Ausfahrt im Tunnel nehmen soll. Woher soll das Navi wissen, wo man gerade ist? Richtig: Es fusioniert die Fahrzeugsensoren und berechnet damit die Position so gut es geht.

Nun denkt man sich: OK, wenn ich zuletzt am Tunneleingang war und mit 50km/h fahre, dann kann das Navi ja exakt ausrechnen, wo (x=Position) man sich 1 Minute (t=Zeit) später befindet:

Soweit die perfekte Welt. Doch das Ausrechnen übernimmt ein Mikrocontroller und dieser ist auf Sensoren angewiesen. Sowohl die Sensoren haben zufällige Messabweichungen, die Übertragungsstrecke hat Störungen als auch die Auflösung von CAN-Bus oder Analog-Digitalwandler lassen viele Ungenauigkeiten in die einfach Angabe “Geschwindigkeit” kommen. Beispielsweise sieht ein Geschwindigkeitssignal so aus:
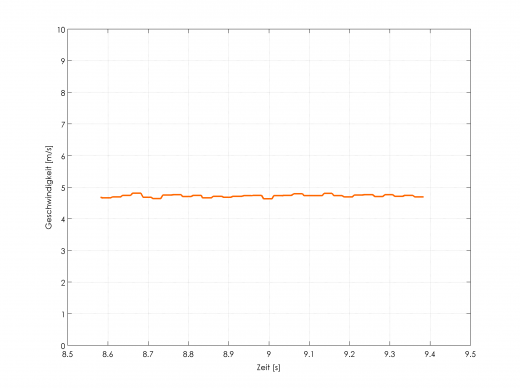
Geschwindigkeits-Zeit-Verlauf einer Messung
Im Mittel stimmt die gemessene Geschwindigkeit schon, allerdings gibt es gewisses “Rauschen”. Berechnet man ein Histogramm der ermittelten Geschwindigkeiten, so sieht man, dass die ermittelten Werte ungefähr einer Normalverteilung unterliegen.
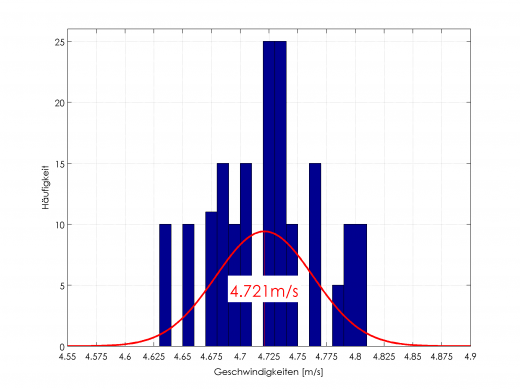
Histogramm der gemessenen Geschwindigkeit mit Normalverteilung
Es gibt also einen, und wirklich nur einen, Maximalwert (unimodal) und eine Streubreite (Varianz). Ist dies der Fall, so kann man mit einem Trick die Berechnung trotzdem sehr gut durchführen.
Idee des Kalman-Filter in 1 Dimension
Um nicht gleich mit Kanonen auf Spatzen zu schießen, möchte ich die Idee des Kalman-Filter (nach Rudolf Emil Kalman) zunächst nur mit einer Dimension (hier: Entfernung) erläutern. Die nachfolgende Beschreibung ist dem Udacity Kurs CS373 von Prof. Sebastian Thrun entlehnt.
Bekanntes Rauschen hilft
Um die Berechnung trotz Messrauschen optimal durchführen zu können, muss das “wie stark” bekannt sein. Dieses “wie stark” wird mit der Varianz der Normalverteilung ausgedrückt. Diese bestimmt man 1x für den Sensor und nutzt danach nur diese “Unsicherheit” für die Berechnung.
Es wird im Folgenden nun nicht mehr mit absoluten Werten gerechnet, sondern mit Mittelwerten (\(\mu\)) und Varianzen (\(\sigma^2\)) der Normalverteilung. Der Mittelwert der Normalverteilung ist der Wert, den man berechnen möchte, die Varianz gibt an, wie sicher man sich dabei ist. Umso schmaler die Normalverteilung (geringe Varianz), desto sicherer ist man sich mit der Messung. Ein Sensor, welcher 100% exakt misst, hat also eine Varianz von \(\sigma^2=0\) (den gibt es aber nicht).
Neue Messung verbessert die Schätzung
Gehen wir also davon aus, das gerade das GPS Signal verloren gegangen ist und das Navi völlig im Unklaren, wo man sich befindet. Die Varianz ist hoch, die Kurve entsprechend platt. Es herrscht Unsicherheit.
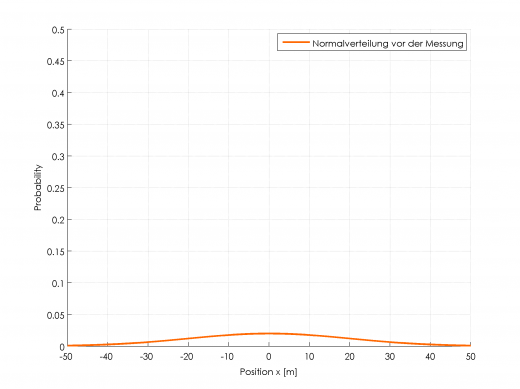
Normalverteilung mit Varianz=20 und Mittelwert=0
Nun kommt eine Geschwindigkeitsmessung vom Sensor, welche mit entsprechender Varianz ebenfalls “ungenau” ist. Diese beiden Unsicherheiten müssen nun miteinander verknüpft werden. Mit Hilfe der Bayes Regel geht die Addition mathematisch korrekt durchzuführen. Prof. Thrun erklärt das im Udacity Kurs CS373 sehr anschaulich:

Der neue Mittelwert ist:

Diese beiden Informationen (eine für die aktuelle Position und eine für die Messunsicherheit des Sensors) ergeben jetzt tatsächlich ein besseres Ergebnis! Die Matlab Implementierung davon ist:
function [new_mean, new_var]=update(mean1,var1,mean2,var2) %% [new_mean, new_var]=update(mean1,var1,mean2,var2) % Berechnet geschätzte Position nach Messung der Position new_mean=(var2*mean1 + var1*mean2) / (var1+var2); new_var = 1/(1/var1 +1/var2);
Umso schmaler die Normalverteilung, umso sicherer ist das Ergebnis.
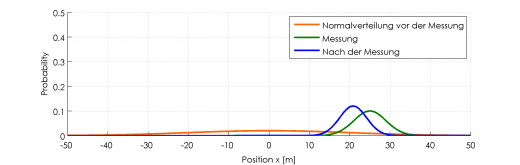
Normalverteilung nach Messung: Trotz unsicherer Messung (grün) und unsicherer Ausgangssituation (orange) ist nun die Positionsbestimmung genauer (blau)
Bewegung verschlechtert die Schätzung
Das Fahrzeug bewegt sich natürlich auch, was sich nachteilig auf die Genauigkeit der Positionsbestimmung auswirkt. Ein Sensor kann z.B. die Umdrehung des Rades bestimmen und über die Annahme, welchen Radius das Rad hat, einen Rückschluss auf die zurückgelegte Strecke treffen, dennoch wird das immer etwas ungenau bleiben. Diese Bewegungsungenauigkeit wird ebenfalls mit einer Normalverteilung beschrieben. Das Zusammenrechnen mit der aktuellen Schätzung läuft dieses mal etwas anders, da die “Bewegung” auch “Vorhersage” genannt werden kann. Man kann nach der Berechnung schätzen, wo man zum nächsten (Mess-)Zeitpunkt sein wird, folglich muss das Ergebnis ungenauer sein, man schaut ja in die Zukunft.


In unserem Beispiel ist das µ einfach v*dt, nämlich die Distanz, die man zurücklegt in der Berechnungszeit.
Die Matlab Implementierung davon ist:
function [new_mean, new_var]=predict(mean1,var1,mean2,var2) %% [new_mean, new_var]=predict(mean1,var1,mean2,var2) % Berechnet neuen Mittelwert und neue Varianz nach Bewegung mit Mittelwert % und Varianz von Ausgangsposition und Unsicherheit der Bewegung sowie % vorhergesagter Bewegungsentfernung % new_mean = mean1 + mean2; % new_var = var1 + var2; new_mean=mean1+mean2; new_var =var1+var2;
Warum nun das ganze?
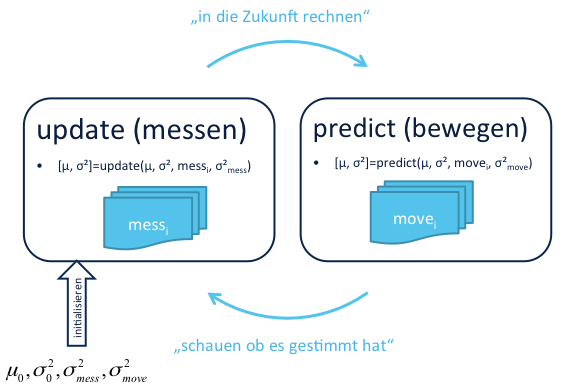
Messen & Updaten: Das Kalman-Filter
Das Kalman-Filter macht nichts anderes als immer wieder diese beiden Funktionen zu berechnen.
%% 1D-Kalman Filter % Aufbau und Erläuterung nach Udacity Kurs CS373 taught by Sebastian Thrun % Paul Balzer clear all, clc %% Ausgangsbedingungen % sigma=Standardabweichung, m = Mittelwert sigma_mess = 4; % Standardabweichung Messung sigma_move = 2; % Standardabweichung Bewegung mu = 0; % Startposition sig = 10000; % Unsicherheit zu Beginn %% Kalman-Berechnung messung = [5, 6, 7, 9, 10]; bewegung= [1, 1, 2, 1, 1]; for i=1:length(messung) [mu,sig]=predict(mu,sig,bewegung(i),sigma_move); disp(['Predict: ' num2str(mu) ', ' num2str(sig)]) [mu,sig]=update(mu,sig,messung(i),sigma_mess); disp(['Update: ' num2str(mu) ', ' num2str(sig)]) end
Das Filter überschreibt zyklisch den Mittelwert (das was mich interessiert) und die Varianz des Ergebnisses. Beim Schritt Messen (update) steigt die Sicherheit des Ergebnisses, beim Schritt Bewegen (predict) sinkt sie. Insgesamt wird sich das Filter allerdings immer sicherer, wo es sich befindet, so lange die Messwerte nicht zu stark vom vorhergesagten Wert abweichen.
Beispiel Positionsbestimmung
Beispielhaft die Berechnung der Position in einem Tunnel, wenn der Predict-Schritt eine Distanz von 20m mit einer Varianz von 0.2 vorhersagt, die tatsächliche Entfernung aber mit einer Varianz von 20 ermittelt wird.
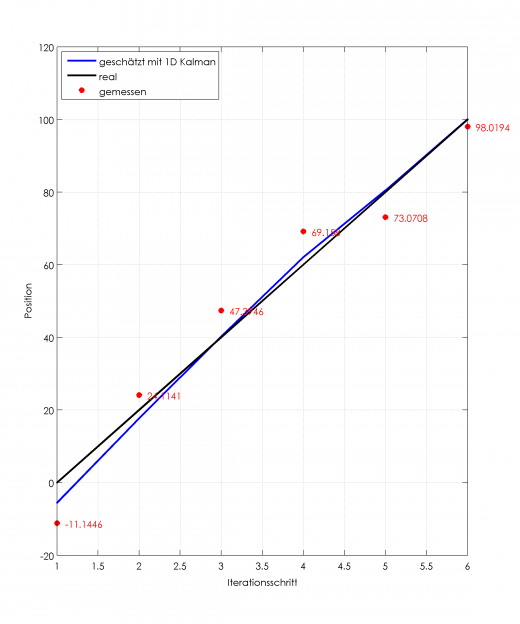
schwarz: Reale Position über Iterationsschritte (Geschwindigkeit=20 Einheiten pro Berechnungsschritt), rot Messwerte mit Messfehlern und in blau die Berechnung mit 1D-Kalman-Filter
Schaut man in den Kern des Kalman-Filters während der 6 Iterationsschritte, so erkennt man, wie die Varianz sinkt (Wahrscheinlichkeit richtig zu liegen steigt!).
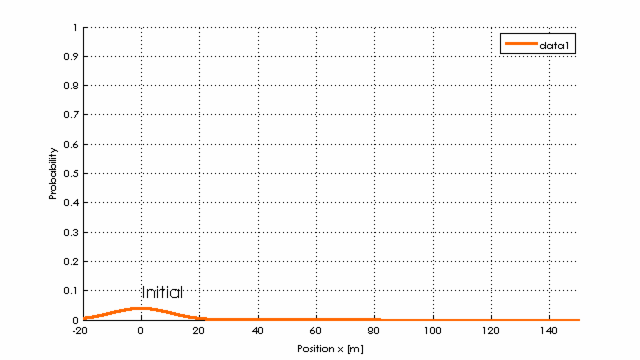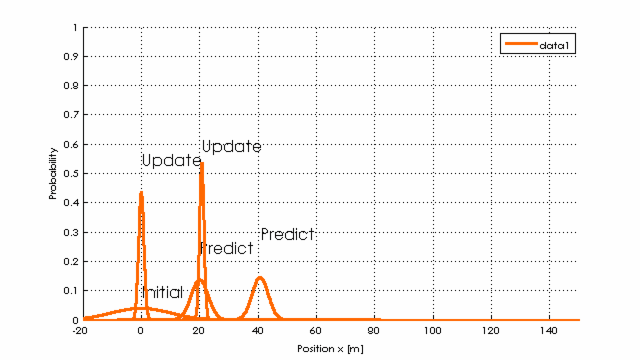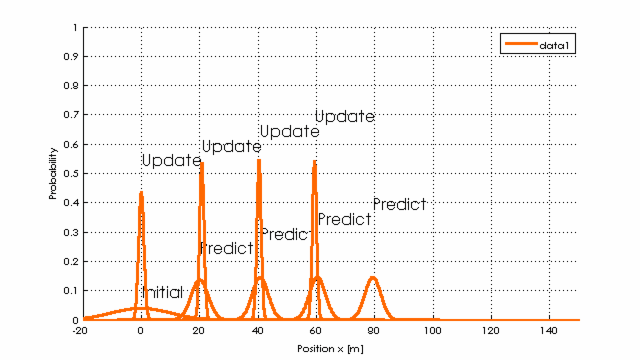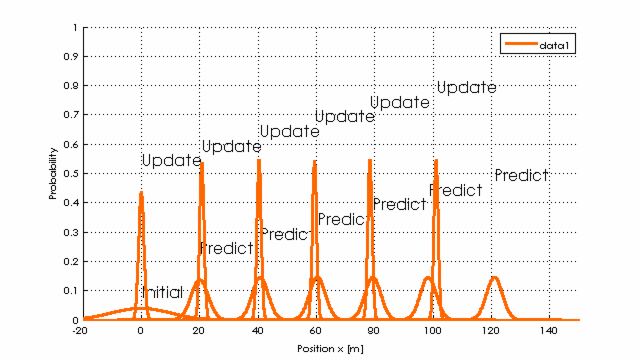
Umgangssprachlich: Da die gemessenen Werte (in update) relativ gut zu den vorhergesagten (durch predict) passen, wird sich das Filter immer sicherer, dass es richtig liegt (Normalverteilungen werden schmaler und höher), obwohl die Werte verrauscht sind.
Kalman-Filter, war das nicht eigentlich das mit den ganze Matrizen?
Ja, war es. Das habe ich hier aber alles weg gelassen, weil man es so wesentlich besser versteht. Das Problem ist: Ohne Matrizen kann man nur mit einer Dimension rechnen und das ist nett, aber nicht ausreichend. Deshalb gibt es im 2. Teil:
Multidimensionales Kalman Filter


22 Comments
Hi,
zu deinem Beispiel…
müsste die Standartabweichung der Bewegung (sigma_move) nicht größer sein als der Messung (sigma_mess).
Da ja Informationen verloren gehen …
Hallo Jonas,
die Zahl ist nicht entscheidend dafür, ob da Information verloren geht oder nicht. Es ist die Art, wie die beiden Wahrscheinlichkeiten zusammen gerechnet werden.
Schau mal am Beispiel von “Move”. Dort wird ja, außer bei σ=0, immer etwas aufaddiert. Es muss also bei der Bewegung “ungenauer” werden. Bei der Messung wird, es immer genauer, es sei denn σ=0. Aber wenn σ=0 wäre, ist der Bruch ja nicht definiert. Den Fall müssen wir also ausschließen.
Die Standardabweichung (oder Varianz) sagt nur aus, um wieviel “falsch” die Messung für einen Berechnungsschritt liegen kann.
Hallo,
ich muss demnächst einen Vortrag über den Kalman-Filter machen und finde, dass dieses Beispiel sehr intuitiv ist. Ich würde gerne wissen wie man die letzte Abbildung/Animation erstellen kann. Sowas würde mir noch fehlen! Ansonsten echt top!!!!
Hat mir sehr geholfen :)
Hallo Nils,
danke für das Lob! Die Abbildung kannst du doch nehmen, wenn du möchtest. An sonsten einfach ein GIF erzeugen in jedem Schritt, mit der Gauss Normalverteilung mit der jeweiligen “mu” und “sigma”.
Und ein GIF so:
mygif = 'mysuperawesome.gif'; f = getframe(gcf); [im,map]=rgb2ind(f.cdata,256,'nodither'); imwrite(im,map,mygif,'Delaytime',.1,'Loopcount',inf) for i=1:1:10 % change something with your figure here, because it is animated! f = getframe(gcf); im = rgb2ind(f.cdata,map,'nodither'); imwrite(im,map,mygif,'writemode','append') endHi,
wirklich sehr schöne Einführung! Ich versuche das gerade durchzuarbeiten und bin dabei auf folgendes Problem gestoßen:
Wenn wir nur noch einen Geschwindigkeitssensor haben, wo kommen dann die Werte von Messung[] her? Die möchte ich doch eigentlich anhand der (verauschten) Bewegung berechnen und habe sonst keine Daten außer die Initialisierung.
Lieben Gruß
Dimitrios
Hallo,
ich finde ebenfalls die Einführung sehr schön. Ein kleine Verständnisfrage hätte ich allerdings. In diesem Beispiel rechnest du
1. UpdateFunktion
2. Predict-Funktion
Ist diese Reihenfolge fest vorgeschrieben oder willkürlich?? Im nächsten Beispiel (Multidimensionales Kalman-Filter) wird
1. Prediction-Funktion
2. Correcton-Funktion
gerechnet. Für mein Verständnis ist das eine umgekehrte Reihenfolge.
Danke für die Erklärung im Voraus,
gruß Oliver
Hi Oliver, da hast du absolut Recht, die Wortwahl ist wirklich sehr verwirrend. Das ist mir bei den Videos vom Prof. Thrun auch schon aufgefallen.
Ich wollte die aber zur Erläuterung nutzen und musste dann auch meinen Code etc. so nennen, dass man es nachvollziehen kann und das zu den Videos passt.
Du solltest da vielleicht das Wort ‘predict’ nicht so ernst nehmen. Die Reihenfolge ist nicht beliebig. Zuerst der Schritt, der die Varianz verbessert, dann der, der die Varianz verschlechtert (also größer werden lässt). So wie es beim Multidimensionalen Kalman Filter ist (und übrigens auch in dem animierten GIF hier beim eindimensionalen).
Viele Grüße
Hallo Paul,
danke für den tollen Beitrag. Ich versuche das gerade zu verstehen und habe auch das Beispiel mit Matlab einmal durchgerechnet. Du schreibst dass sich das Filter imer sicherer wird, richtig zu liegen. Woher weiß der Filter dass er richtig liegt?
Sieht man sich die berechnungen der Varianzen in update und im predict an, so ist dort kein Bezug zur “Richtigkeit” bzw. zur Position/Beschleunigung. Die Varianz konvergiert bei mir auch in Matlab immer gegen den gleichen wert – egal welche position oder messwerte ich eingebe…
Da stimmt doch was nicht oder verstehe ich da was nicht?
Viele Grüße,
Joe
Würden Sie bitte noch den Code veröffentlichen, mit dem Sie dieses Bild erstellt haben – danke
https://www.cbcity.de/wp-content/uploads/2013/05/1D-Kalman-Ablauf-geschatzte-Position-520×624.png
Vielen Herzlichen Dank,
Mustererkennung Klausur kommen. Wirklich sehr gut erklärt.
Danke für die verständliche Einführung.
Vorschlag: Um den Zusammenhang mit dem mehrdimensionalen Fall zu verdeutlichen, könnte man die Formel für µneu noch umformen zu
µneu = µ1 + k * (µ2 – µ1) mit k := σ1^2 / (σ1^2 + σ2^2). k liegt dann zwischen 0 und 1 und gibt an, ob wir µ1 oder µ2 stärker vertrauen.
Das ist die beste Erläuterung bzw. die einzige, wo ich der mit Statistik auf Kriegsfuß steht, einen Aha-Effekt hatte :-) Ich überlege gerade wie man das am besten auf die SOC Schätzung oder Berechnung (state of charge, verbleibende Kapazität oder Energie in einer Batterie) transferiert. Diese lässt sich über die Messung der Zellspannung nur dann direkt bestimmen, wenn die Zellen zuvor ein paar Stunden unbelastet waren (beim Elektroauto also beim Aufstarten, wenn das Auto die Nacht über in der Garage stand oder nach der Arbeit). Denn unter Last brechen die Zellspannungen beim Fahren bis zu 400mV (also grob 50% SOC) ein und brauchen Stunden bis sie wieder relaxt sind. Der Innenwiderstand der Lithiumzelle ist bei Minustemperaturen deutlich höher als bei Plus. Nun könnte man einfach die Ah mit Shunt-Stromsensor zählen, was auch bei manchen Anwendungen funktioniert, aber der Messfehler addiert sich über die Zeit zunehmend auf (z.B. Hybridbatterien pendeln nur zwischen 30 und 70%, um die Lebensdauer zu erhöhen). Neben den Zellspannungen und dem Batteriestrom werden auch die Temperaturen in der Batterie auf dem Gehäuse der Zellen und Stromschienen gemessen.
Can you share additional real-world examples or case studies where the Kalman Filter has been successfully applied, and the impact it has had in terms of accuracy and reliability?